
So its final project time at GA, and after much deliberation, I have decided that I want to get my hands dirty with some Natural Language Processing (NLP). I intend to look at amazon customer reviews, and using NLP establish a model that can (for that product category) predict the likely star rating a customer would give that product.
This sort of sentiment analysis would be helpful to both the product team of a website, to hone in on the words that would encourage customers to make a purchase in a products description; And to a customer service team, who can establish some triggers in order to follow up with customers following a poor review.
What's Next
Well I'd better get scraping again to go and fetch enough reviews, and then I'll process these reviews and have a group of words that are most associated with a 5 star review.
Product Scraping
Amazon are pretty good sports in this regard, their robots.txt they don't say don't scrape our products. great!
Scraping Products
Before I can scrape reviews, I need to get a bunch of products to scrape reviews from. I'll scrape products from entire categories at a time.
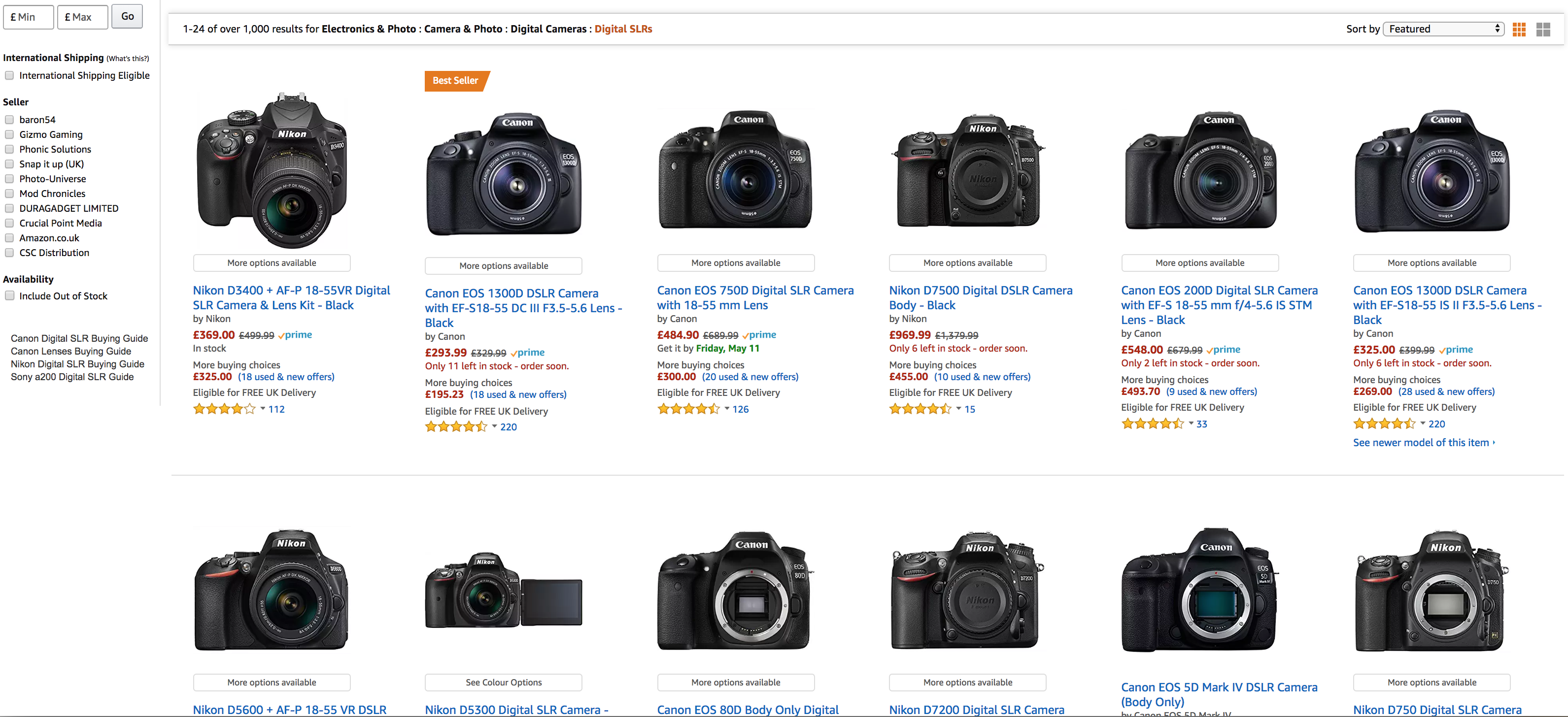
Here you see products from the Digital Camera/ Digital SLR category. The important parts to capture at this point are:
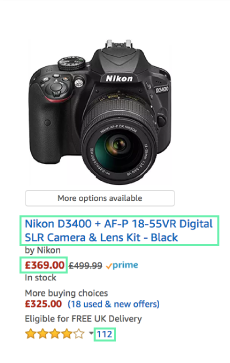
- asin - the unique identifier that Amazon uses per product
- title - the product title
- number of reviews
- price
I'm not especially interested in getting the overall star rating for the product at this point, because "Amazon calculates a product’s star ratings using a machine learned model instead of a raw data average. The machine learned model takes into account factors including: the age of a review, helpfulness votes by customers and whether the reviews are from verified purchases."[1]
The asin is hidden in the site html rather than displayed, but thats not a problem..
I'll write a function to collect these details, and then if there are more pages of results, move on to the next page and continue. I'll store the results in a dictionary, which will make for easy inspection with pandas later on.
Review Scraping
Once I have all the products I want to scrape reviews for here, I can then go and get all the individual customer reviews for each product.
Turning all the asins and titles into a URL is pretty straightforward, as Amazon uses a uniform URL structure for categories:
We also know that they show 10 reviews per page, and we have already got the number of reviews that each product has, so we can establish the number of review pages that each product will have to be scraped.
Knowing all the review page urls ahead of time is going to allow us to save a lot of time over the scrape, we can use the power of multi-threading to call urls in parallel rather than waiting for one thread to call each url sequentially.
Let's build a function that will create a pool of threads, and scrape reviews.
from multiprocessing.pool import ThreadPool
def async_get(urls):
ls_=[] #list to store result
pool = ThreadPool(12) #generate a pool of 12 threads
results = pool.map_async(function, urls) #map the function across all urls
results.wait() # blocking
ls_.append(results.get()) #store the result of the latest thread in the list
pool.close() #close the pool
pool.join() #close all threads
return ls_ #return the list of scraped reviews
I chose 12 threads simply because that was the maximum I could run at a time without causing my computer grief..
The code for scraping the reviews from each page is probably a bit too long for here, but I've added over at My Github
Next Up: Review Analysis
taken directly from Amazon's review pages. ↩︎
Comments