
I'd never been to Addis Ababa, the venue for ICLR 2020. I still haven't. But I did manage to attend ICLR 2020.
The organising committe did an amazing job at readying a site to host the conference online, and I think sets a really good precedent to allow future conferences a rich remote experience either alongside or instead of the physical thing.
Navigation
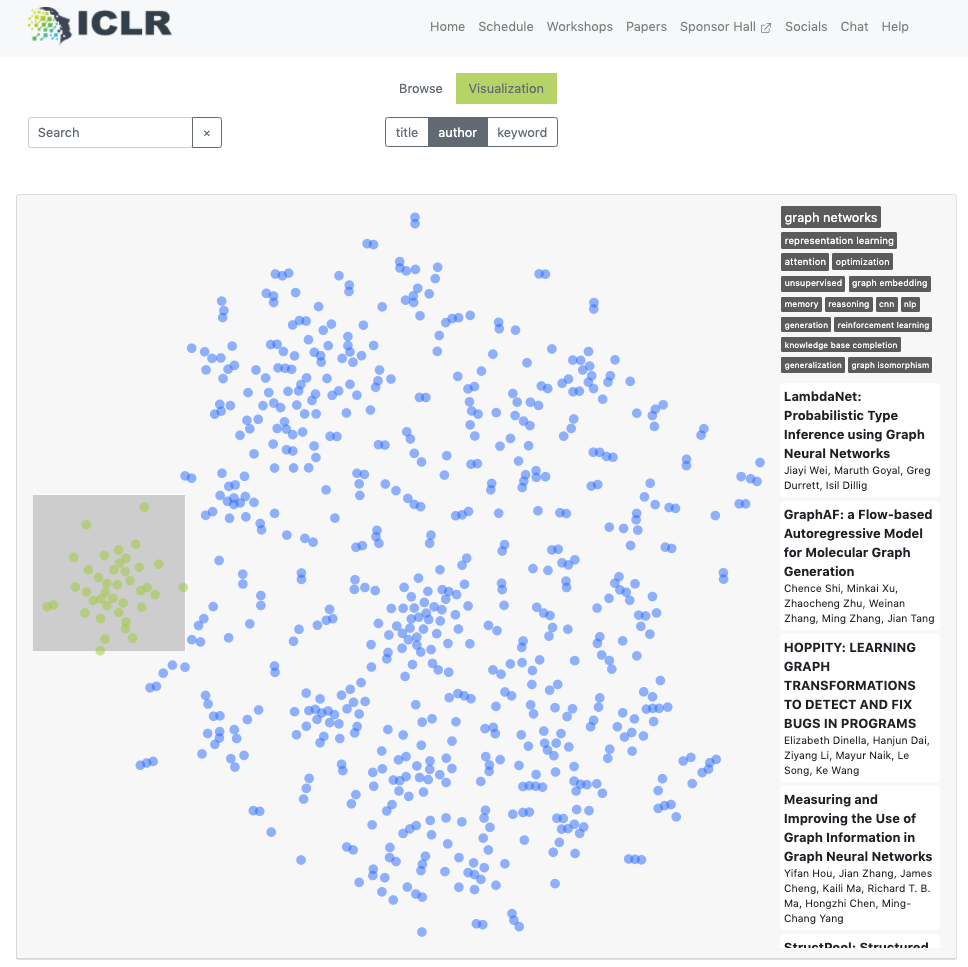
The killer feature in this site: T-SNE VISION! papers embedded into 2d space so you could descover papers that were thematically similar. Magical. Selecting a square of the space would bring up a list of the papers within that space and give keywords for the region.
I'm amazed I haven't seen this kind of search interface exposed in more places. Definitely fitting that the first place I saw it was for this AI conference.
Format
Typically throughtout the day at a conference you'd choose a track/theme to follow, and plant yourself in that room for a session, then hear all the 5 minute oral presentations from speakers who'd dangle the interesting parts of the paper and invite you to talk them over at the poster session later. This could mean that if you wanted to see different presentations that were in different tracks then you'd be forced to choose which to miss if getting between the rooms wasn't possible in time. Not So here! Pick and choose which to listen to / watch at a time to suit you. Also being able to pause to take notes is super underrated.
Poster sessions now moved to the virtual world, were chat sessions in the side panel of the oral presentation. You could read the conversations that had happened before, where if your question had been asked, you needn't ask the presenter again.
Content
With Hundreds of papers/talks to see it would be impossible to get to everything, so I didn't.
with the scope of papers being broad, I tended to stick to the papers that would provide the greatest source of inspiration for features / improvements to things that we are using day to day at Datasine - this naturally meant that I didn't see many of the robotics/reinforcement learning papers.
Heres a couple papers that i thought were interesting for the problems we are looking to solve:

Restricting the Flow: Information Bottlenecks for Attribution
This paper aimed to allow fine grained heatmaps for pixel wise attribution for image classification. By restricting the flow of information through the intermediate layers of the network and observing the loss, they can build up maps of which pixels are pertinent to the classification and the amount of information an image region provides for the network’s decision, indicated as bits per pixel.
Github Code

A CRITICAL ANALYSIS OF SELF-SUPERVISION, OR WHAT WE CAN LEARN FROM A SINGLE IMAGE
Currently there is a lot of work being done to pre train image networks on a selfr supervised task to learn good representations before fine-tuning on a later task. This approach has been particularly useful for training networks with little labelled data. There are three methods for self supervised learninng examined here: BiGAN, RotNet and DeepCluster. The Paper looked to adress whether this pre-training exercise can effectively leverage the information held in images during pre-training by training these methods using either a dataset of 1 million different images, or 1 image randomly cropped 1 million times. Intuition would say that pre-training on 1 million images would be more useful for downstream tasks. They find that this is true, but not by sufficient a margin to show that only learning on one image is enough, and that this method of self supervision is only really learning the augmentation method.
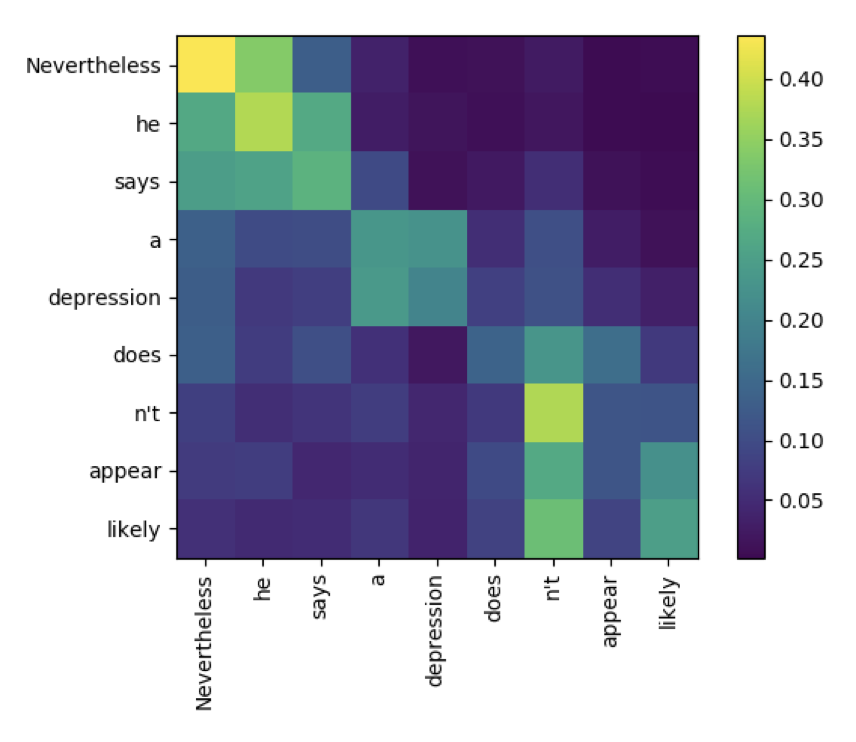
Are Pre-trained Language Models Aware of Phrases?
Observing attention heatmaps in pretrained language models, it can be seen that phrases are captured when attention looks like a box on what might usually look like an identity matrix. Spurred by this observaton that phrases are identified, the authors set about to apply a method to derive the constituency trees without any additional training. The author leverages the concept of syntactic distance between words to be able to derive constiuency trees. They show that for English their method provides a strong baseline for grammar induction
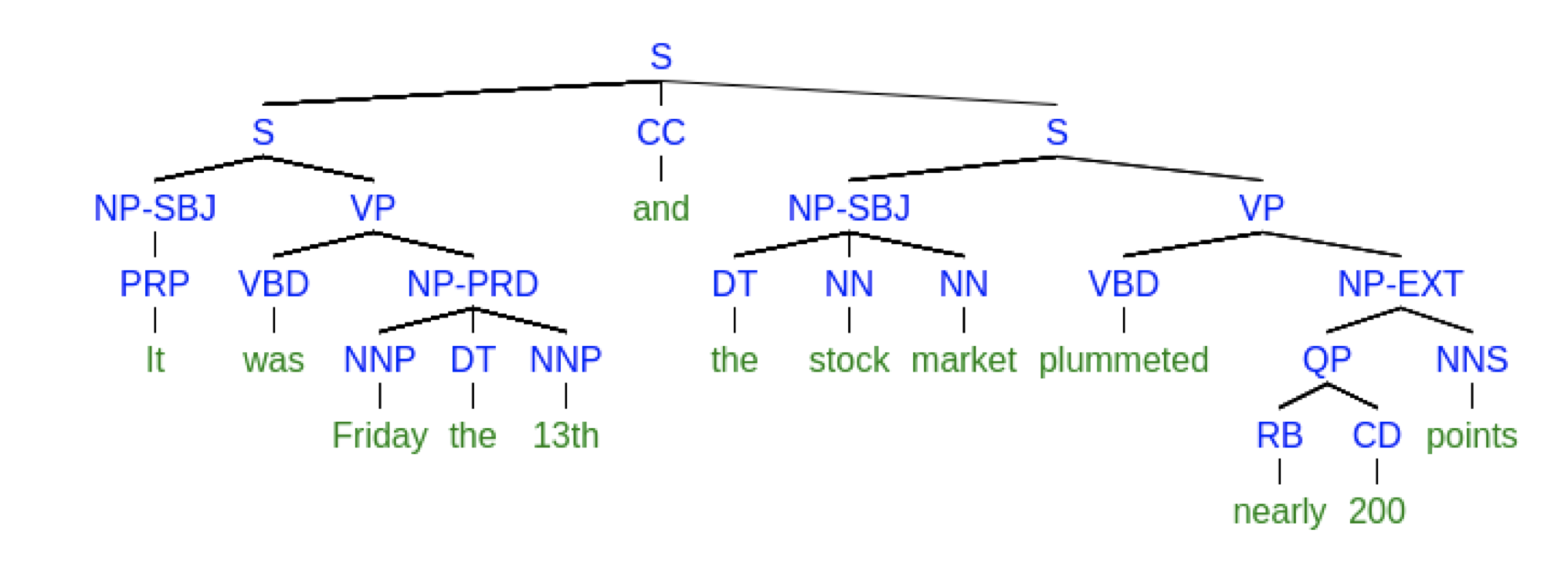

Neural Machine Translation with Universal Visual Representation
Neural Machine Translation that has been grounded in images has been hampered by the fact that there are few image caption datasets with parallel captions for the same image in multiple languages. This paper addresses the lack of parallel captions by training a monolingual image caption embedding and then identifying 'topics' within images. A lookup store can be created such that when given an source language sentence, the closest image representations are found and a caption in the target language can be returned enabling translation.
RESIDUAL ENERGY-BASED MODELS FOR TEXT GENERATION
Autoregressive language models operate at the token level, and aim to predict the next word given a context. This can lead to problems at inference because the model is conditioning ite generation on what it has generated before, and also the greedy nature of generation can mean that over time the generation becomes less and less coherent as there is no look-ahead. The authors propose an energy based model to operate at the sequence level and using BERT to act as a discriminator in assessing the generated sequences as being written by human or machine.
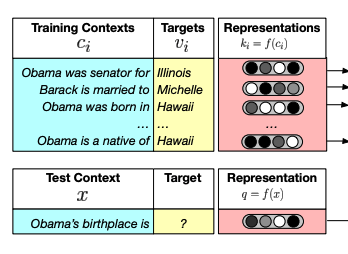
Generalization through Memorization: Nearest Neighbor Language Models
This paper gives an idea for how language models can easily permit some domain addaptation by the addition of a data store for lookup when predicting te next word in a phrase. The intuition is that if you create a data store of left context vectors as index and then the target word as value, at test time the predicted word can be 'predicted' by lookup of closest context vecor in the data store
There are heaps more but I'll keep this short..
Keynote Talks
There were some cracking keynote talks from some luminaries in the field, hopefully these will gradually surface on youtube or similar. Ones that I particularly enjoyed:
- AI Systems That Can See And Talk by Prof. Devi Parikh which gave a great general overview of the current state of AI with regards vision based tasks such as Visaul Question Answering.
- Doing for Our Robots What Nature Did For Us from Prof. Leslie Kaelbling was a really great talk on understanding the computational problems necessary to make a general purpose intelligent robot
- AI + Africa = Global Innovation from Dr. Aisha Walcott-Bryant covered how we could leverage AI to transform health systems and imporving global health, using examples rooted in African Healthcare with regards Malaria plannning and Maternal, Newborn and Child Health
Comments