
ELI5: Cookie dough of the NN world
Imagine you were a chef and you were going to bake some cookies, but after making the cookie dough mix you decided that was the best bit and then just stopped baking.
Ultimately that is what we want to achieve with word2vec. We build the platform to make predictions of surrounding words given an input word but just throw away the predictions and keep the vector embeddings of the input words.
The objective
To learn word vector representations of words, and to speed up the process of training the NN to learn these embeddings.
The How:
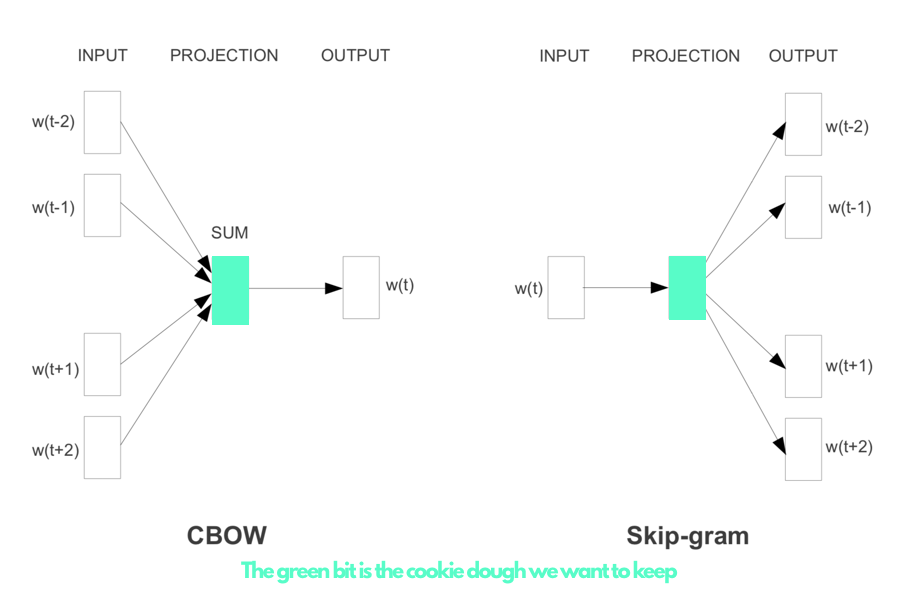
2 methods of training a neural net, either given a word predict context (skip-gram) or given context predict word (CBOW).
This method was utilised by Mikolov et al. in 2013 Link with an update paper shortly after which improved training time and accuracy in certain tasks Link
How does it work?
CBOW
The inital paper utilised the continuous bag of words method to, given a context window of words, predict the word that is most probable in that context eg given a context of (boy, ball) we would aim to maximise the probability that the middle word would be 'kicks' over other words wich would not make sense.
Skip - gram
The network:
input: a one hot vector (input word)
embedding layer
output - heirarchical softmax one hot vector (context word)
Also mentioned in the initial paper but elaborated on in the second, the skip gram method is the reverse of the CBOW. Given an input word, can we predict the words in the context window? When the window is large the accuracy is better, but at the cost of computing time. The words that are further away from the input word in the window are down weighted as they are often less related. Using the words from the example earlier, we would be giving a word 'kicks' and trying to predict (boy, ball) as the context
 Mikolov et al 2013
Mikolov et al 2013
Things would take a lot of time with a big vocabulary - If we were projecting to a vector of size 300 (as Google did) and with a vocabulary of let's say 20,000 words we would for each word need to update 300 * 20,000 weights = 6 million weights
Subsampling
We don't need to keep updating the vector for the word 'the'. If we subsample the most frequently used words in the corpus, we will pick up word enough times to still generate good vectors
Learning Phrase Vectors
On the forst pass of the corpus look at individual words. Then on next pass, look at words that appear more commonly alongside other words than on their own and make 2 word phrases. Repeat for longer phrases. eg 'Maple' -> 'Maple Leafs' -> 'Toronto Maple Leafs'. These phrases can then be treated as individual entities like "Toronto_Maple_Leafs" to learn vectors which would be better than the average vector for the words that make up the phrase.
Hierarchical softmax
This is the final layer in the network, we need to sqeeze the probability for all of the words in the output layer to sum to one so the softmax is used,
Negative Sampling
In the Skip-gram model, the output layer is a one hot encoded vector for each of the words in our context, where we want a 1 in the right column for words that are contextually 'right' and a 0 for words which would not be correct. Rather than having to set the 0 for all words and updating the weights in the network for them, we could do this for only a smaller sample because, as long as our corpus is big enough, as we go through the training we will eventually cover all words enough to converge anyway.
Comments