on
10 minutes to read
Why Do Multi-Agent LLM Systems Fail?
MAST (Multi-Agent System Failure Taxonomy)
Why Do Multi Agent LLM Systems Fail
A useful paper that captures a taxonomy of failure cases in agent systems, specifically where multiple agents are involved. My key take home here, beyond the useful taxonomy is the observation that a strong verifier can improve outcomes, but a verifier alone is not sufficient. In combination with an LLM as a judge, the taxonomy makes the identification of failure cases over full conversational traces much easier for developers to diagnose and correct.
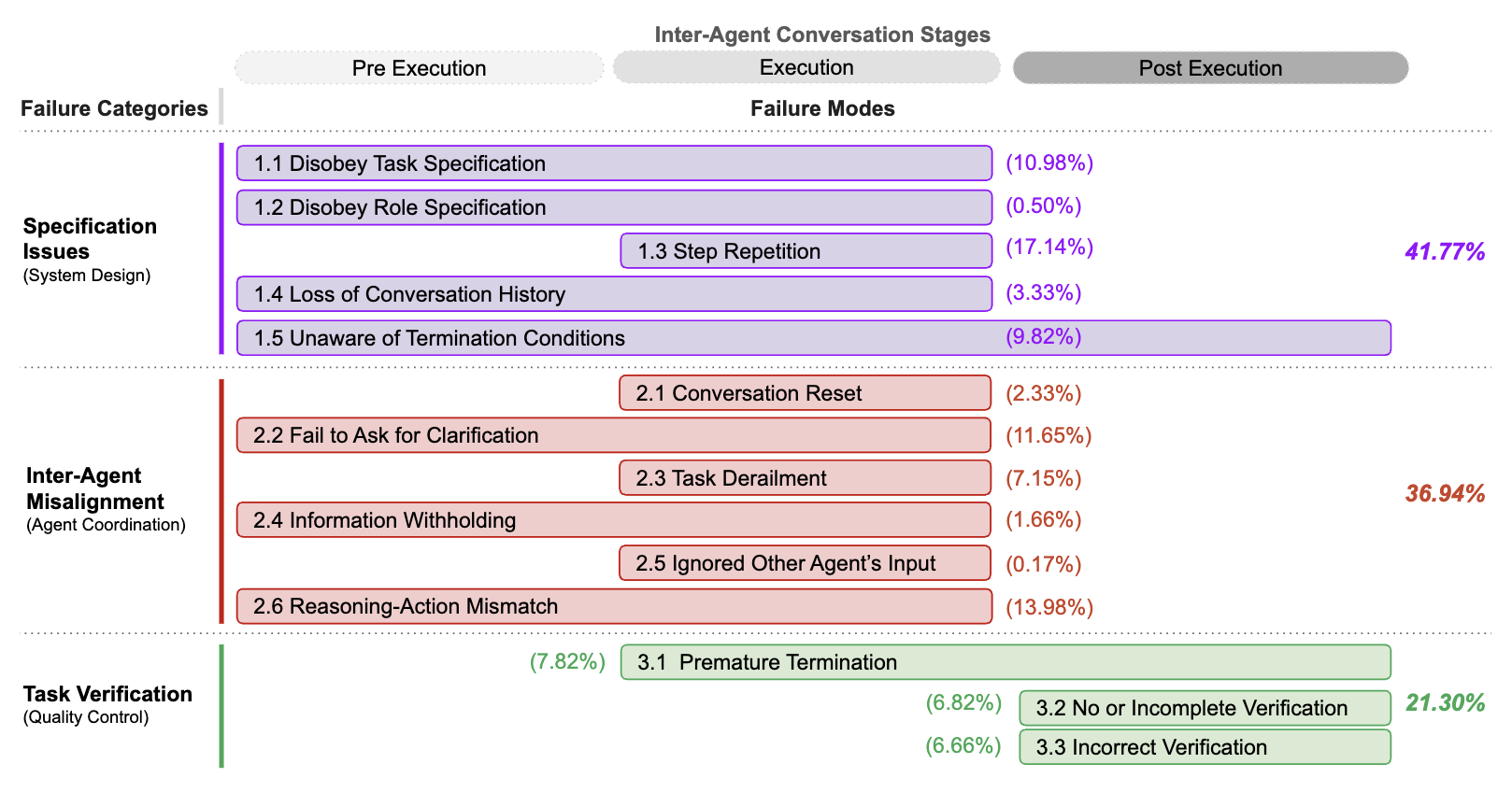 If a failure mode spans multiple stages, it means the issue involves or can occur at
different stages. Percentages represent how frequently each failure mode and category appeared in our analysis of 200+
traces
If a failure mode spans multiple stages, it means the issue involves or can occur at
different stages. Percentages represent how frequently each failure mode and category appeared in our analysis of 200+
traces
They identify 14 unique failure modes, organized into 3 overarching categories:
(i) specification issues,
| Code | Failure Mode | Description |
|---|---|---|
| FM-1.1 | Disobey task specification | Failure to adhere to the specified constraints or requirements of a given task, leading to suboptimal or incorrect outcomes. |
| FM-1.2 | Disobey role specification | Failure to adhere to the defined responsibilities and constraints of an assigned role, potentially leading to an agent behaving like another. |
| FM-1.3 | Step repetition | Unnecessary reiteration of previously completed steps in a process, potentially causing delays or errors in task completion. |
| FM-1.4 | Loss of conversation history | Unexpected context truncation, disregarding recent interaction history and reverting to an antecedent conversational state. |
| FM-1.5 | Unaware of termination conditions | Lack of recognition or understanding of the criteria that should trigger the termination of the agents’ interaction, potentially leading to unnecessary continuation. |
(ii) inter-agent misalignment
| Code | Failure Mode | Description |
|---|---|---|
| FM-2.1 | Conversation reset | Unexpected or unwarranted restarting of a dialogue, potentially losing context and progress made in the interaction. |
| FM-2.2 | Fail to ask for clarification | Inability to request additional information when faced with unclear or incomplete data, potentially resulting in incorrect actions. |
| FM-2.3 | Task derailment | Deviation from the intended objective or focus of a given task, potentially resulting in irrelevant or unproductive actions. |
| FM-2.4 | Information withholding | Failure to share or communicate important data or insights that an agent possesses and could impact decision-making of other agents if shared. |
| FM-2.5 | Ignored other agent’s input | Disregarding or failing to adequately consider input or recommendations provided by other agents in the system, potentially leading to suboptimal decisions or missed opportunities for collaboration. |
| FM-2.6 | Reasoning-action mismatch | Discrepancy between the logical reasoning process and the actual actions taken by the agent, potentially resulting in unexpected or undesired behaviors. |
(iii) task verification.
| Code | Failure Mode | Description |
|---|---|---|
| FM-3.1 | Premature termination | Ending a dialogue, interaction or task before all necessary information has been exchanged or objectives have been met, potentially resulting in incomplete or incorrect outcomes. |
| FM-3.2 | No or incomplete verification | (Partial) omission of proper checking or confirmation of task outcomes or system outputs, potentially allowing errors or inconsistencies to propagate undetected. |
| FM-3.3 | Incorrect verification | Failure to adequately validate or cross-check crucial information or decisions during the iterations, potentially leading to errors or vulnerabilities in the system. |
Key Observations
Many failures came from system design, not just limitations of the underlying LLMs (e.g., hallucination or basic prompt following). Although improved models are beneficial, our results suggest that they are insufficient alone to guarantee reliable MAS performance.
“The presence of a verifier is not a silver bullet. Despite having verifiers, overall MAS success rates can be astonishingly low, where ChatDev achieves only 33.33% correctness on ProgramDev. We discovered during end-to-end human examination of the trace that current verifiers often only perform superficial checks (e.g., missing comments or code compilation) and struggle to ensure deeper correctness. we introduce an additional verification step in ChatDev focusing on high-level task objectives, supplementing existing code-level checks. This relatively simple architectural change yields a notable +15.6% absolute improvement in task success on ProgramDev demonstrating that enhancing verification, particularly at different abstraction levels, is beneficial.”
“Verification should act as the final line of defense. If a failure originates earlier and the verifier fails to catch it, MAST correctly attributes the failure to its origin, not merely as a verification failure”
Using LLM as a Judge OpenAI o1 with a custom prompt Notebook They achieve a 94% accuracy at identifying the failure cases over examplar traces
from openai import OpenAI
import re
openai_api_key = "KEY"
client = OpenAI(
api_key=openai_api_key,
)
def chat_completion_request_openai(prompt):
messages = [
{"role": "user", "content": prompt}
]
chat_response = client.chat.completions.create(
model='o1',
messages=messages,
temperature=1.0)
if chat_response.choices:
completion_text = chat_response.choices[0].message.content
else:
completion_text = None
return completion_text
definitions = open("taxonomy_definitions_examples/definitions.txt", "r").read()
def openai_evaluator(trace, definitions=definitions, examples=''):
prompt = (
"Below I will provide a multiagent system trace. provide me an analysis of the failure modes and inefficiencies as I will say below. \n"
"In the traces, analyze the system behaviour."
"There are several failure modes in multiagent systems I identified. I will provide them below. Tell me if you encounter any of them, as a binary yes or no. \n"
"Also, give me a one sentence (be brief) summary of the problems with the inefficiencies or failure modes in the trace. Only mark a failure mode if you can provide an example of it in the trace, and specify that in your summary at the end"
"Also tell me whether the task is successfully completed or not, as a binary yes or no."
"At the very end, I provide you with the definitions of the failure modes and inefficiencies. After the definitions, I will provide you with examples of the failure modes and inefficiencies for you to understand them better."
"Tell me if you encounter any of them between the @@ symbols as I will say below, as a binary yes or no."
"Here are the things you should answer. Start after the @@ sign and end before the next @@ sign (do not include the @@ symbols in your answer):"
"*** begin of things you should answer *** @@"
"A. Freeform text summary of the problems with the inefficiencies or failure modes in the trace: <summary>"
"B. Whether the task is successfully completed or not: <yes or no>"
"C. Whether you encounter any of the failure modes or inefficiencies:"
"1.1 Disobey Task Specification: <yes or no>"
"1.2 Disobey Role Specification: <yes or no>"
"1.3 Step Repetition: <yes or no>"
"1.4 Loss of Conversation History: <yes or no>"
"1.5 Unaware of Termination Conditions: <yes or no>"
"2.1 Conversation Reset: <yes or no>"
"2.2 Fail to Ask for Clarification: <yes or no>"
"2.3 Task Derailment: <yes or no>"
"2.4 Information Withholding: <yes or no>"
"2.5 Ignored Other Agent's Input: <yes or no>"
"2.6 Action-Reasoning Mismatch: <yes or no>"
"3.1 Premature Termination: <yes or no>"
"3.2 No or Incorrect Verification: <yes or no>"
"3.3 Weak Verification: <yes or no>"
"@@*** end of your answer ***"
"An example answer is: \n"
"A. The task is not completed due to disobeying role specification as agents went rogue and started to chat with each other instead of completing the task. Agents derailed and verifier is not strong enough to detect it.\n"
"B. no \n"
"C. \n"
"1.1 no \n"
"1.2 no \n"
"1.3 no \n"
"1.4 no \n"
"1.5 no \n"
"1.6 yes \n"
"2.1 no \n"
"2.2 no \n"
"2.3 yes \n"
"2.4 no \n"
"2.5 no \n"
"2.6 yes \n"
"2.7 no \n"
"3.1 no \n"
"3.2 yes \n"
"3.3 no \n"
"Here is the trace: \n"
f"{trace}"
"Also, here are the explanations (definitions) of the failure modes and inefficiencies: \n"
f"{definitions} \n"
"Here are some examples of the failure modes and inefficiencies: \n"
f"{examples}"
)
return chat_completion_request_openai(prompt)