on
9 minutes to read
Self Improvement
A comprehensive look at how AI systems are learning to improve themselves
“It is not the most intellectual of the species that survives; it is not the strongest that survives; but the species that survives is the one that is able best to adapt and adjust to the changing environment in which it finds itself.” - Charles Darwin
Self-Evolving Agents: The Next Phase of AI Development
A comprehensive review of self-evolving agents
This survey paper is a really interesting read and deserves a little TL;DR-ifying to capture the key parts
The Core Framework: What, When, and How
As LLMs have been deployed in agentic patterns over many open ended tasks, a newer paradigm of agent has become necessary where previous static tooling such as RAG for knowledge retrieval have become bottlenecks in the completion of tasks. In order for agents to improve over time, they must be able to adapt to novel and evolving contexts becoming more robust, versatile, and capable of tackling complex, dynamic real-world problems.
After formally defining envrionment, agent systems, self evolution strategy and the objective of self evolving agents, the researchers organise the paper around around three core questions central to autonomous improvement: “What aspects of an agent should evolve? When should adaptation occur? And how should that evolution be implemented in practice?”
The authors have alsoo helpfully linked all cited papers in their GitHub Repo
What Can Evolve? (Four Core Components)
1. Models - The Cognitive Core
The most direct form of evolution involves the agent’s core reasoning capabilities. Rather than relying on expensive human-annotated training data, these systems employ clever self-play mechanisms. In one approach called SCA (Self-Correcting Agents), the model alternates between two roles: a “Challenger” that generates complex coding problems and an “Executor” that solves them. Successful solutions become training data, creating a self-improvement loop that’s both cost-effective and targeted to areas where the model struggles.
2. Context - Memory and Prompt Optimisation
Context evolution operates on two levels. Memory evolution asks “how should we store, forget, and retrieve past experiences to stay informed?” Advanced systems like Mem0 implement pipelines that extract key facts from recent interactions and decide whether to ADD new knowledge, MERGE redundant information, or DELETE contradictions.
Prompt optimisation focuses on “how can we phrase instructions so the LLM behaves better?” Frameworks like DSPy treat entire workflows as graphs where sub-prompts are jointly optimised over global objectives.
3. Tools - From User to Creator
Agents are transitioning from being just tool users to autonomous tool makers. This progression is explored along three axes:
- Discovery: Creating specialised tools on-demand rather than relying on fixed toolsets
- Mastery: Iteratively refining newly created tools through self-correction loops that analyse compiler errors, API responses, and environmental feedback
- Management: As tool libraries grow into the hundreds or thousands, agents must efficiently select and compose tools for complex multi-step problems
4. Architecture: System-Level Optimisation
Both single-agent and multi-agent systems can evolve their fundamental structure. Single agents might use “textual gradients” to propagate feedback through complex workflows, while multi-agent systems automatically adapt their communication patterns and role assignments. Some cutting-edge systems like Darwin Gödel Machine allow agents to directly rewrite their own Python code.
When Does Evolution Happen? (Two Temporal Modes)
Intra-test-time Evolution occurs during task execution. The agent adapts in real-time, using immediate feedback to adjust its approach while solving the current problem. This synchronous improvement is computationally intensive but enables rapid adaptation.
Inter-test-time Evolution happens between tasks. After completing a problem, the agent extracts feedback signals, identifies patterns of success and failure, and systematically refines its capabilities for future use. This retrospective learning decouples performance from improvement, allowing for more thorough analysis.
How Do They Evolve? (Three Main Paradigms)
1. Reward-based Evolution
This approach uses various feedback signals to guide improvement:
- Textual feedback provides detailed, interpretable critiques in natural language
- Internal confidence-based rewards exploit the model’s own probability estimates and certainty measures
- External rewards come from environment responses, majority voting, or explicit rules
2. Imitation and Demonstration Learning
Agents learn by reproducing successful behavioral patterns, either from their own high-quality outputs or from other agents and external sources. This bootstrapping approach is particularly effective when good examples are available.
3. Population-based Methods Using evolutionary algorithms, multiple agent variants compete and reproduce based on performance: pure Darwinism
Real-World Applications
The survey categorises applications into general domain improvements and specialised fields:
General Domain: Memory-driven agents that accumulate experience across diverse tasks, curriculum learning systems that progressively increase difficulty, and model-agent co-evolution where the underlying LLM and agent architecture improve together.
Specialised Domains:
- Coding: Agents that learn new programming patterns and debugging strategies
- GUI Interaction: Systems that adapt to new interfaces and user preferences
- Financial Trading: Agents that evolve strategies based on market feedback
- Medical Diagnosis: Systems that refine diagnostic capabilities through case experience
- Education: Tutoring agents that adapt to individual learning styles
The Evaluation Challenge
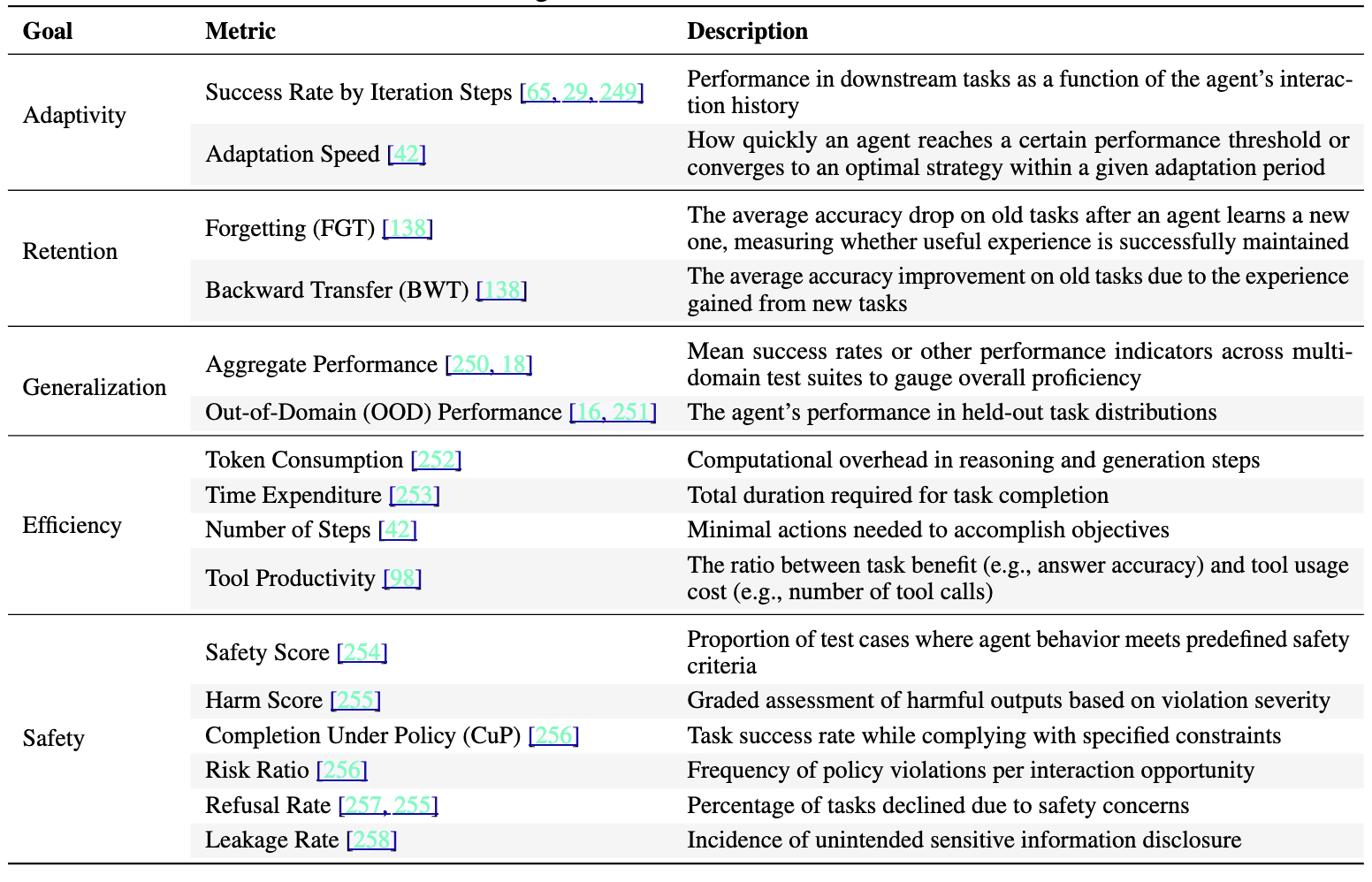
Measuring self-evolving systems requires new metrics beyond traditional benchmarks:
Five Core Metrics:
- Adaptivity: improvement on in domain tasks through experience: Success Rate by iteration Steps
- Retention: observing that new knowledge learned does not have deleterious consequence on previously successful tasks through ‘forgetting’ Measured in accuracy delta on old tasks after acquisition of new skill
- Generalisation: The application of in domain knowledge to out of domain tasks
- Efficiency: Cost, speed, number of turns, number of required tool interactions in order to complete given tasks
- Safety: Adherence to predetermined safety guiderails and propensity for harmful action measured over time.
Three Assessment Approaches:
- Static assessment: Traditional snapshot performance
- Short-horizon adaptive assessment: Quick learning capability - important to have a quick measure to determine feasibility of a proposed solution, before iterating towards the longer horizon problems.
- Long-horizon lifelong learning: Sustained improvement over time
Useful Parts to Remember
The “Curse of Abundance”: As agents master hundreds or thousands of tools, selecting and composing the right combination becomes computationally challenging. Traditional retrieval methods become slow and inaccurate with massive tool libraries.
Catastrophic Forgetting: Balancing the acquisition of new skills with retention of existing capabilities remains an open challenge.
Self Play Instead of relying on expensive human-annotated data or low-quality synthetic data, self-evolving agents create high-quality training data through self-play:
- Cost-effective: No human annotation required
- Targeted: Generates data specifically for areas where the model struggles
- Scalable: Can generate unlimited training examples
- Quality-controlled: Only uses successful solutions for training
Environment: Agent environment is a partially observable Markov Decision Process. formalisation captures the complex, partially observable, goal-driven nature of real-world agent environments, where:
POMDP Components: Environment = (G, S, A, T, R, Ω, O, γ)
Goals (G): Set of task objectives the agent must achieve
- Examples: User queries, specific problem-solving tasks
- Each goal g ∈ G defines what success looks like
States (S): Internal environmental states
- Represents the true state of the environment
- Not directly observable by the agent (hence “partially observable”)
Actions (A): Agent’s available behaviors
- Textual reasoning - Thinking and planning in natural language
- External knowledge retrieval - Accessing databases, search engines
- Tool calls - Using APIs, executing code, manipulating systems
Transition Function (T): State evolution dynamics
-
T (s' s,a) = probability of reaching state s' from state s after action a - Models how the environment changes in response to agent actions
Reward Function (R): Goal-conditioned feedback mechanism
- R(s,a,g) → scalar score or textual feedback
- Conditions rewards on specific goals, enabling multi-objective learning
- Can provide both numerical scores and natural language critiques
Observations (Ω): What the agent can perceive
- Limited view of the true environment state
- Forces agents to maintain internal models and handle uncertainty
Observation Function (O): Perception dynamics
-
O(o' s,a) = probability of observing o' given state s and action a - Probability distribution over next observation
Discount Factor (γ): Future reward weighting
- Balances immediate vs. long-term objectives (temporal credit assigment)
Agent Architecture
At its core, a multi-agent system can be formally defined as Π = (Γ, {ψi}, {Ci}, {Wi}), where:
- Γ (Architecture): The control flow and collaborative structure organizing agents as a sequence of nodes
- ψi (Model): The underlying LLM/MLLM at each node
- Ci (Context): Contextual information including prompts and memory at each node
- Wi (Tools): Available tools and APIs at each node
Each node executes a policy function that maps observations to action probabilities across both natural language and tool spaces.
Taxonomy of related Papers
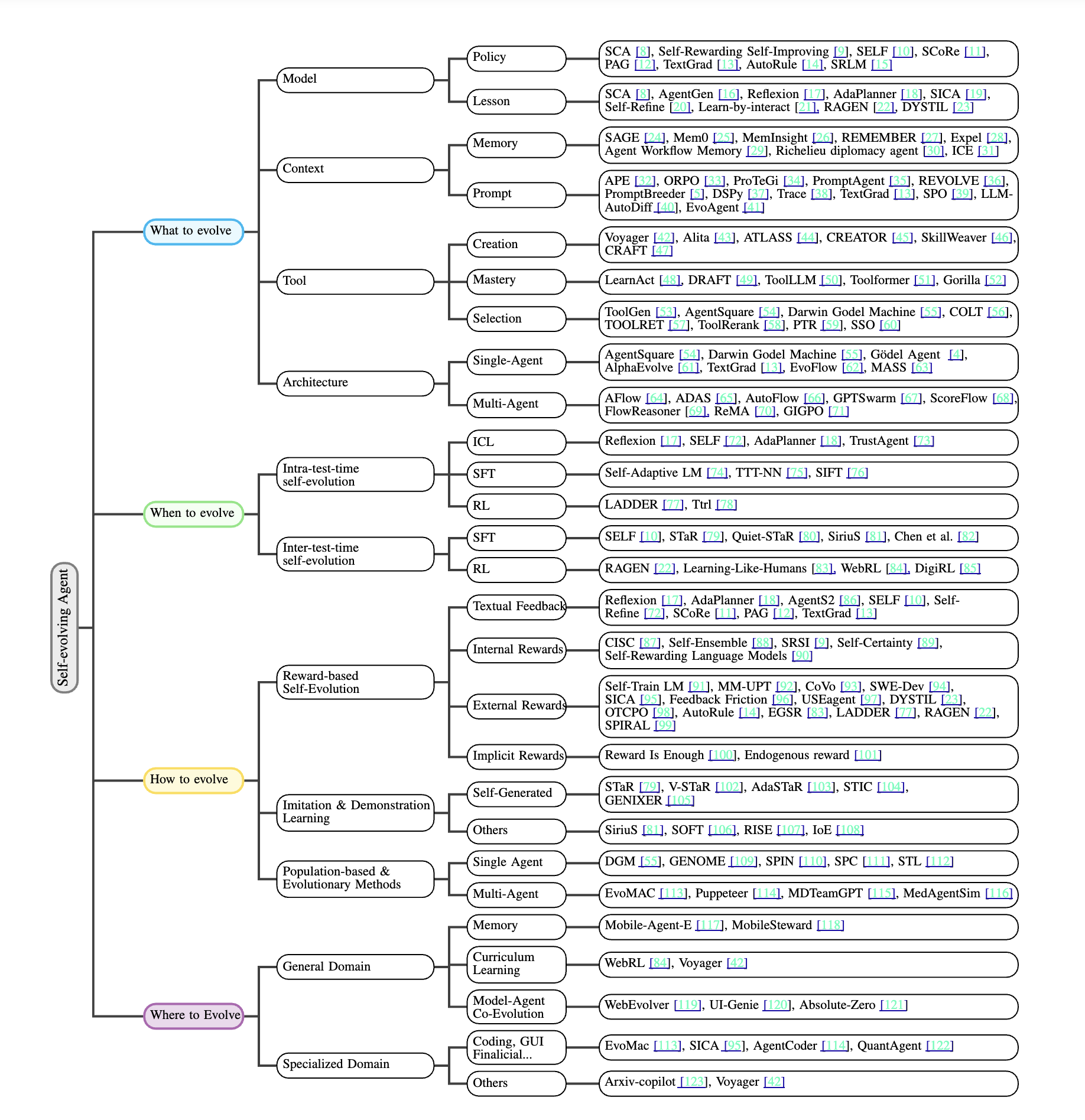
The overarching objective in designing a self-evolving agent is to construct a strategy such that the cumulative utility over tasks is maximized