on
3 minutes to read
ALHF
Agent Learning through Human Feedback (DataBricks)
I do have a bit of a soft spot for Databricks/Mosaic, otherwise this post could have just been a tweet. However their post caught me during a bit of a reading and thinking spree over agent behaviour, and this struck me as a useful personalisation case - using memory.
The Problem with Feedback
Any learning needs data; for improvement to happen, a system needs to receive some feedback on a particular task such that it can learn to do more of the good things, or less of the bad things.
As agent patterns have become more and more used for specific niche tasks, the data required to train models on these tasks has not kept pace. Specialised tasks come with specialist requirements that need specialist data, which has probably been labelled by specialist humans; that is to say, it is time consuming and expensive.
Enter the Agents
Well, enter the humans and the agents really. The key idea in ALHF is that specialist humans are likely to be using the specialist systems and if they are using the systems then they are ideally placed to provide immediate natural language feedback over the trajectory of a task. If the user can input some feedback over the course of a task, then the system should be able to learn from that.
Example Case
Databricks examine the setup over a QA dataset they hold, and pose questions for agents to respond to where there may be some ambiguity - e.g. different flavours of SQL have different functions for week of year calculation - answers may be factually correct, but when given feedback that the user is specifically working with postgres, the follow up answers should all be correct for that setup
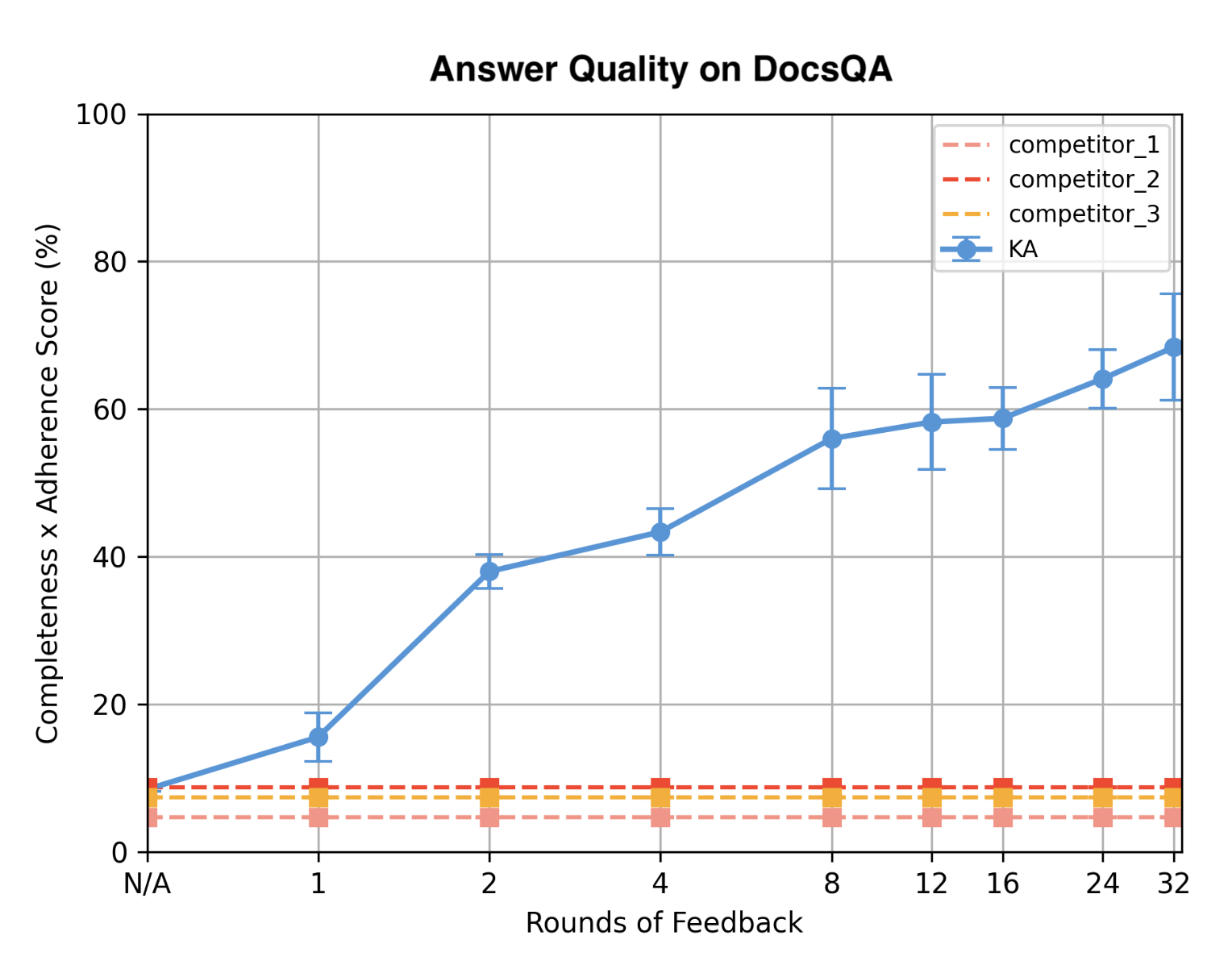 response quality (as measured by Answer Completeness and Feedback Adherence) increases with increasing amounts of feedback.
response quality (as measured by Answer Completeness and Feedback Adherence) increases with increasing amounts of feedback.
When to apply feedback
Feedback needs only to be applied later in a conversation when it is relevant; it is not always necessary. If it was always necessary, it would be easy to add it to context at every interaction, but that would be inefficient. The proposed solution is memory to allow the agent to store and retrieve feedback when it may be relevant to the given interaction
Assignment
As systems are usually multiple components, the system must know where to assign the relevant feedback to be useful later. The proposed solution involves each component exposes the ability to accept feedback and adjust its behaviour appropriately. This they refer to as scoping “determining the right scope of applicability for each piece of feedback. Or alternatively put, determining the relevance of a piece of feedback to a question.”
Key Observations
Specialist Feedback is important and natural language feedback within the trajectory is as useful as labelled specialist data.
Duration The bulk of improvement looks to have come from 8 rounds of feedback. In the post they refer to feedback records as opposed to rounds in the graph, so we can perhaps assume this means 8 user inputs relating to suggestions towards improving trajectory.
Personalisation Some aspect of this process feels more akin to personalisation rather than overall domain specialisation - the agent is not getting better at SQL, but better at answering vendor specific SQL questions in the face of underspecification in questions.
Memory allowing agent access to memory is the real win here, exposing memories when appropriate and keeping context clear.