on
5 minutes to read
GEPA
Refelctive Prompt Optimisation can Outperform Reinforcement Learning
It should come as no surprise here that the paper starts off with a quick dig against old data-hungry reinforcement learning. When you have the data, and specifically the volume of data, RL can do wonderful things. When data is scarce, we must look for signal from within.
It is unsurprising because we can see that final author from the paper is Omar Khattab, creator of prompt optimising framework DSPy.
TL;DR GEPA is prompt optimisation turbo charged by rich feedback and evolutionary principles.
Data Feedback
The core claim, which is well backed up, is that the rich traces from conversational histories are a goldmine for improving the performance of a given agent system. When the internal ‘thinking’ traces of sub modules can be observed as well as their outputs then there is plenty of opportunity for reflection on the process and identification of the weaknesses. In this case we consider feedback to be the judgement of an LLM over the thought and output traces, rather than direct human feedback.
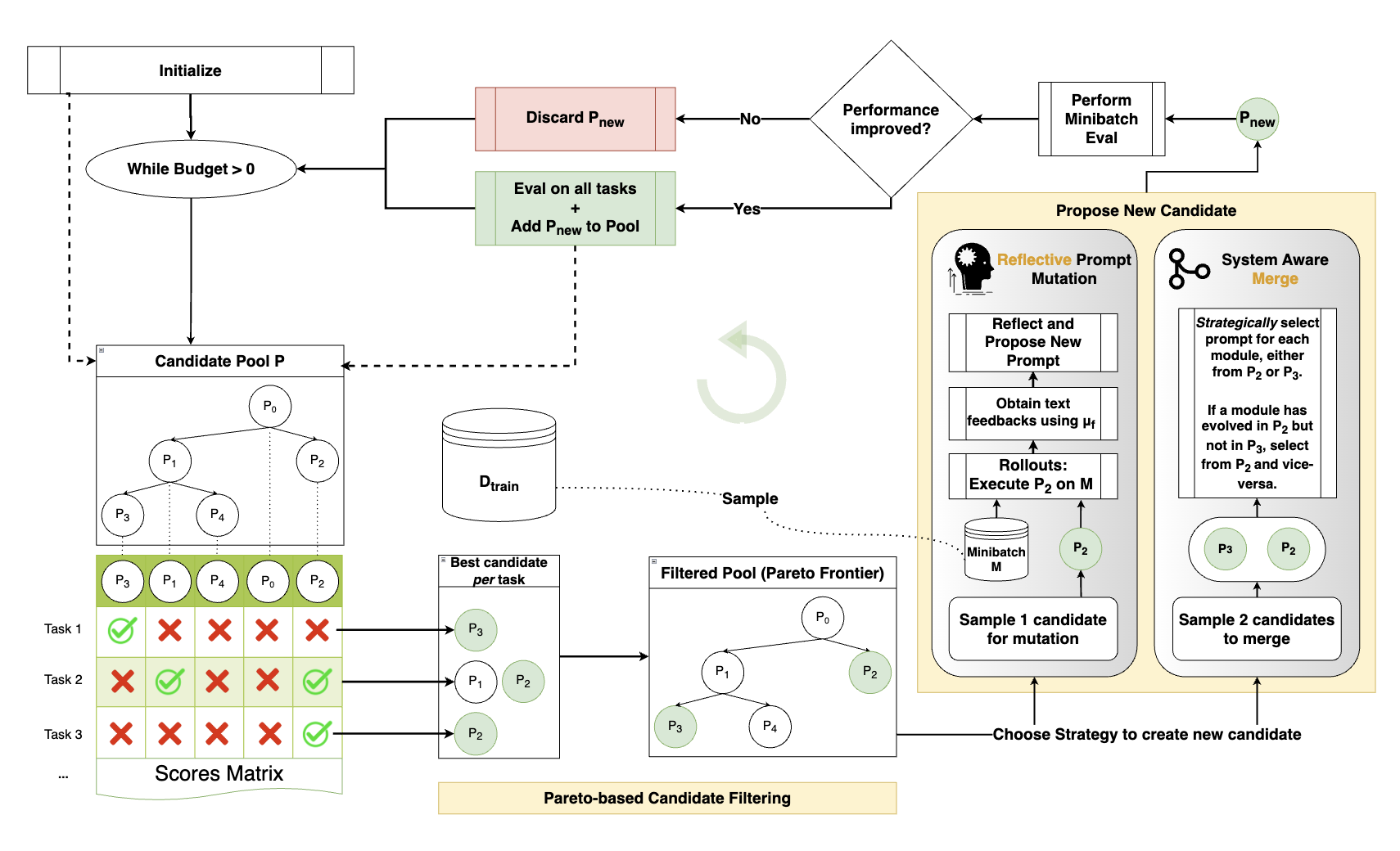
GEPA (Genetic-Pareto)
The reflective prompt optimiser for compound AI systems merges the reflection step with an evolutionary search for the best system prompt. Each module in the system will have a system prompt that can be tuned to perform optimally, this iterative process mutates the prompts in that direction.
Pareto?
I thought that was economics? Well its a handy principle here - when there is a tradeoff between two things, a pareto front can be established which indicates the maximum possible combination between two things and the effect that improving along one axis will affect the other axis. The front is used in this case to avoid the system settling on a local optimum prompt from one problem instance, but explores each sub module prompt to perform best over the full problem set. The front exposes the highest score achieved for each individual training instance across all candidates in the pool.
Compound AI System Definition
Always handy to have a definition of agents - so lets share their definition:
Φ = (M, C, X , Y)
| Component | Description |
|---|---|
M |
A collection of language modules, ⟨M1, . . . , M│M│⟩. |
C |
The control flow logic that orchestrates module invocation. It can call modules in any sequence and multiple times. |
X, Y |
The global input and output schemas for the entire system. |
Each module
Mi = (πi, θi, Xi, Yi) is an LLM subcomponent:
| Component | Description |
|---|---|
πi |
The system prompt for module Mi, including instructions and few-shot demonstrations. |
θi |
The underlying model weights for module Mi. |
Xi, Yi |
The input and output schemas specific to module Mi. |
Control Flow
C orchestrates the sequencing and invocation of modules and can invoke different modules in any order multiples of times.
Training Loop
GEPA’s training loop uses an evolutionary approach, creating new candidate solutions through mutation and crossover. Mutation refers to the modification of the best prompt, wheras crossover is the merging of multiple top performing prompts. Learning occurs from past attempts by tracking each candidate’s ancestry and incorporating feedback from new tests allowing improvements to accumulate over time.
The Pareto frontier is used to identify the top performing candidates for each specific task. It then filters this group to keep only those with “winning” strategies and prunes any that are clearly outperformed by others. Finally, it stochastically selects from the refined list, preferring candidates that excelled across a wider range of tasks.
 a complicated diagram of a for loop
a complicated diagram of a for loop
Results
GEPA achieves state-of-the-art performance on several benchmarks (HotpotQA, IFBench, HoVer, and PUPA) with significantly fewer rollouts than existing methods like GRPO—up to 35 times fewer. It surpasses GRPO’s performance by up to 19% on these tasks and matches its validation scores with up to 78 times greater sample efficiency. GEPA+Merge, shows an even greater performance gain of 21% over GRPO.
Key Observations
Natural language traces generated during the execution of a compound AI system offer rich visibility into the behavior and responsibilities of each module, as they capture the intermediate inferences and underlying reasoning steps. Reflection allows credit assignment to the relevant modules in oeder to update the whole system behaviour.
Reflective prompt evolution enables instruction optimisation alone to outperform joint instruction and few-shot optimisation (existing DSPy methods)