on
5 minutes to read
Large Concept Models
LLMs thinking in concepts, not just word by word
Large Concept Models - Meta
Meta just released this paper: large concept models language modeling in a sentence representation space which really scratches an itch I’ve had for a while. The analogy they use is that of a presenter giving a speech many times, where they have a good idea of the points they want to cover but not a word for word script. “The goal of this paper is to provide a proof of concept of this high-level vision of an alternative architecture to current best practice in language modeling”
The paper is really well worth digging into, because they really throw the kitchen sink at a ‘proof of concept’ with several throughly tested possible architectures. I’m aiming here to just cover the idea at a really high level.
The Problem with Token-Based Models
Imagine you’re a language model stranded on a desert island looking for treasure.
Token-based Large Language Models (LLMs) would approach this problem by learning the probable direction before having arrived at the island and then taking each step rigidly, one at a time—placing one foot in front of the other and hoping to reach “X marks the spot.” If a mistake occurs early, such as a wrong step or misunderstanding the terrain, the rigid approach can lead the model astray.
Now imagine a different approach: instead of blindly following footsteps, you’re equipped with a compass that points to the treasure, no matter where you are on the island. You can adapt, explore, and navigate creatively, knowing the compass aligns you with your ultimate destination. This is how target embeddings work in Large Concept Models (LCMs)—guiding the reasoning process toward the desired output while allowing flexibility along the way.
Enter Large Concept Models (LCMs)
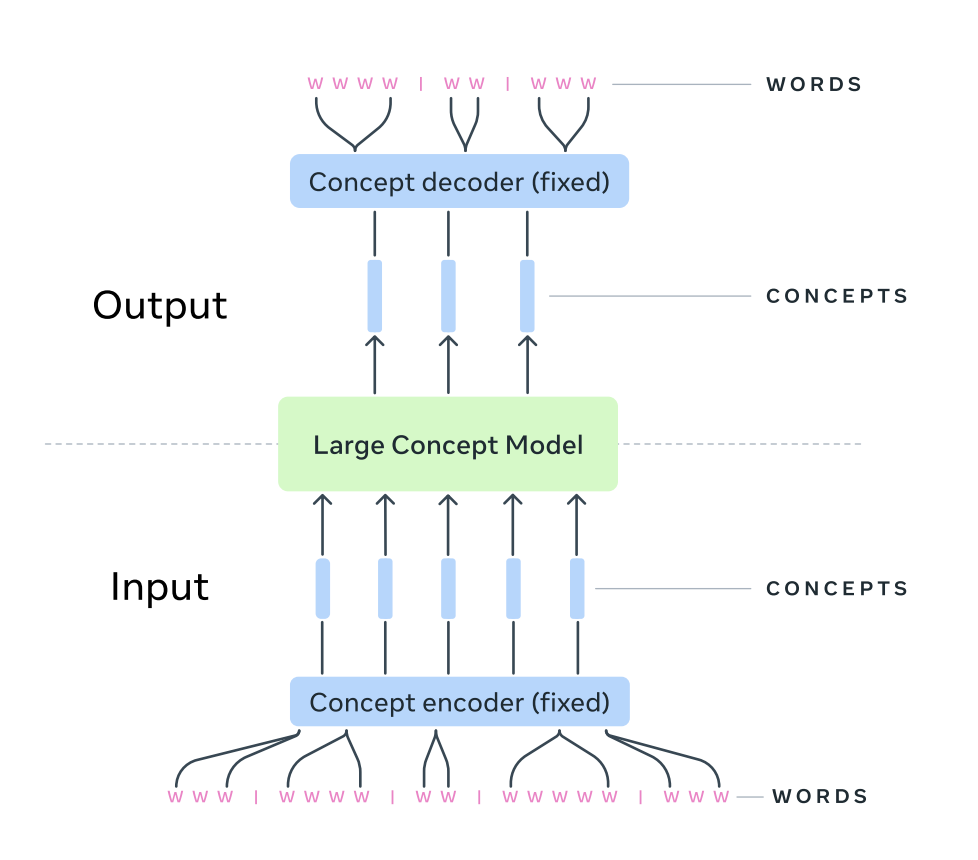
LCMs are built to reason at a higher level of abstraction, representing ideas not as sequences of tokens but as concepts in an embedding space. A “concept” corresponds to an entire sentence—a semantically rich, language-independent unit of meaning. This shift allows LCMs to focus on where to go (the embedding “X marks the spot”) rather than obsessing over every tiny step along the way.
LCMs draw inspiration from diffusion-based image generation models like DALL-E or Stable Diffusion. These models use a process of refining noise into coherent visuals, guided by CLIP embeddings that align high-level textual descriptions (“a treasure chest on a beach”) with generated images. Similarly, LCMs refine sentence embeddings in the SONAR space to generate coherent and structured outputs aligned with a conceptual goal.
How LCMs Use the Treasure Map Approach
Lets try and clarify the analogy a little..
Target Embedding as the Compass
The concept embedding acts as a compass. The model knows where the “treasure” is (the concept it wants to generate) and iteratively works toward it. Unlike rigid, step-by-step navigation, this approach allows LCMs to adapt dynamically, avoiding obstacles or refining noisy inputs while ensuring they stay on course.
Refining Ideas Through Iteration
Like clarifying a blurry map, LCMs use a process similar to image diffusion. Starting from a noisy or rough representation of the concept, they progressively refine it into a detailed sentence embedding. Each iteration reduces the “noise” and aligns the output more closely with the target.
Hierarchical Reasoning: Planning and Executing
While the compass guides the destination, LCMs also plan their journey hierarchically. They generate high-level outlines (abstract embeddings) and refine them into detailed outputs. This layered reasoning is akin to outlining a route on the map before setting off, ensuring every step aligns with the bigger picture.
Multimodal Flexibility
SONAR embeddings enable LCMs to operate seamlessly across 200+ languages and modalities, treating text, speech, or even experimental sign language encodings as interchangeable inputs. Our compass works in any terrain, pointing the way regardless of the language or modality.
Results That Speak Volumes
LCMs consistently outperform token-based models in multilingual and multimodal tasks by:
- Balancing Flexibility and Focus: They adapt creatively while maintaining alignment with their goal.
- Hierarchical Consistency: By reasoning layer by layer, they generate outputs that are structured and coherent over long contexts.
- Generalization Across Tasks: Whether summarizing, expanding text, or generating in zero-shot conditions, LCMs deliver results aligned with the target embedding.
Why It Matters
Large Concept Models represent a fundamental shift in AI reasoning. By replacing token-by-token micromanagement with goal-oriented abstraction, they combine the precision of a compass with the creativity of an adaptable explorer. The result? AI systems capable of generating coherent, structured, and truly multilingual content while tackling complex reasoning tasks with ease.
Whether it’s finding “X marks the spot” or crafting a nuanced multilingual summary, LCMs demonstrate that embedding-based reasoning is the smarter way forward.