on
8 minutes to read
Gemma Scope
Open Sparse Autoencoders Everywhere All At Once on Gemma 2
Gemma Scope: Unlocking Sparse Autoencoders for All
If you’ve been following recent developments in interpretability research, you’ll know that Sparse Autoencoders (SAEs) have rapidly become one of the most exciting tools for peeking into the black box of neural networks. The potential is tantalizing: what if we could decompose a model’s internal activations into interpretable, human-friendly features? Could we finally see what a model is really doing under the hood?
What is Gemma Scope?
Gemma Scope is an open suite of JumpReLU Sparse Autoencoders trained on Google DeepMind’s Gemma 2 family of models. These SAEs have been trained to decompose the activations of Gemma models (2B, 9B, and partially 27B) across all layers and sublayers. The result is a massive release of more than 400 SAEs that contain over 30 million interpretable features.
The engineering feat behind Gemma Scope is remarkable—it required more than 20% of GPT-3’s training compute, 20 Pebibytes of activations stored on disk, and billions of SAE parameters learned. More kitchen sink thrown at this from the Google team 🎉
Why Sparse Autoencoders Matter
SAEs allow us to reconstruct neural network activations as sparse, interpretable combinations of directions. Unlike dense and opaque activations, SAEs introduce sparsity—a small number of activated “latents” at any time—which often align with human-interpretable features. Imagine having a dictionary of directions where each direction corresponds to a concept like negation, syntax, or a particular emotion. That’s the dream SAEs push us towards.
However, training SAEs is expensive. Until now, most research in this space was limited to small models or proprietary, industry-guarded weights. Gemma Scope blows this bottleneck wide open.
By releasing pretrained SAEs for Gemma 2 models:
- Anyone can now investigate what features large-scale models are learning.
- Interpretability experiments that were once computationally prohibitive can now be conducted at scale.
- We have a benchmark for testing future improvements in sparse autoencoder methods.
The Gemma Scope team trained their SAEs using the JumpReLU activation function, a variant that thresholds activations while preserving sparsity. Compared to older methods like Top-K or L1-regularized SAEs, JumpReLU strikes a careful balance between reconstruction fidelity and activation sparsity.
JumpReLU also allows for a variable number of active features, unlike Top-K approaches which enforce a fixed number of active dimensions. This flexibility makes JumpReLU particularly powerful when modeling activations where the number of meaningful features changes dynamically across inputs.
To better illustrate how SAEs work, let’s look at the following diagram:
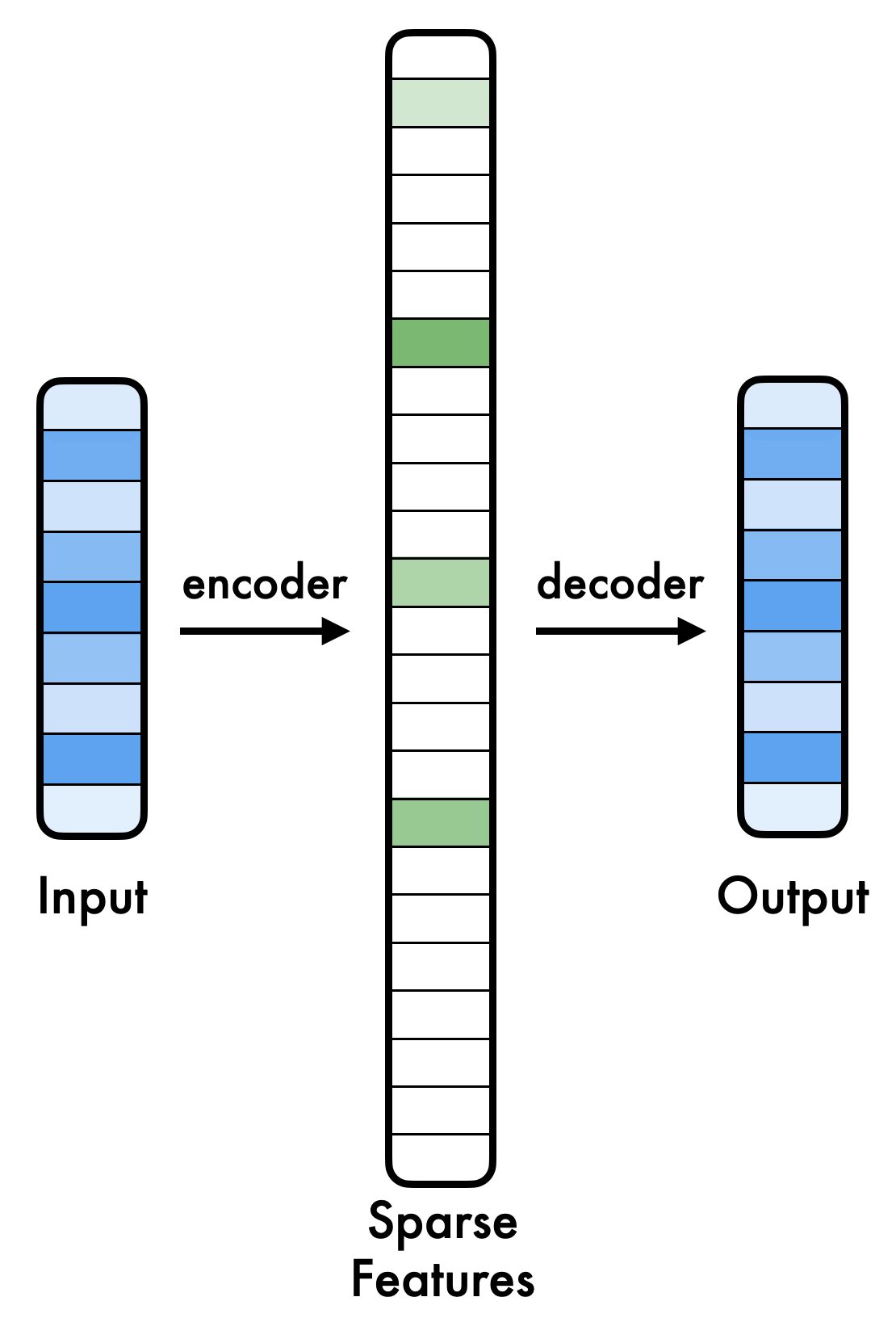
The process can be broken down into three key steps:
- Input: A dense activation vector from a neural network layer is passed into the SAE.
- Sparse Features: The encoder identifies and activates only a small subset of sparse features (highlighted in green) that best represent the input.
- Output: The decoder reconstructs the original input using just the activated sparse features.
This decomposition is crucial for interpretability because the activated sparse features often correspond to human-interpretable directions, making it easier to analyze what the model is representing.
The size of the sparse latent feature must naturally be much larger than the input, to capture as many possible features, and there is a good number of ablations as to the effect of width on performance - hint: the wider the better
Feature spaces of Autoencoders
Sparse Autoencoder - SAE
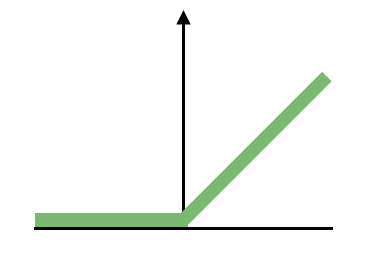 The JumpReLU means the SAE can only have positive values, the ‘jump’ part comes from the Heaviside step fuction, such that it is not just any value above 0, but that for each dimension a threshold is learned above which the value is passed through, otherwise it is set as zero.
The JumpReLU means the SAE can only have positive values, the ‘jump’ part comes from the Heaviside step fuction, such that it is not just any value above 0, but that for each dimension a threshold is learned above which the value is passed through, otherwise it is set as zero. 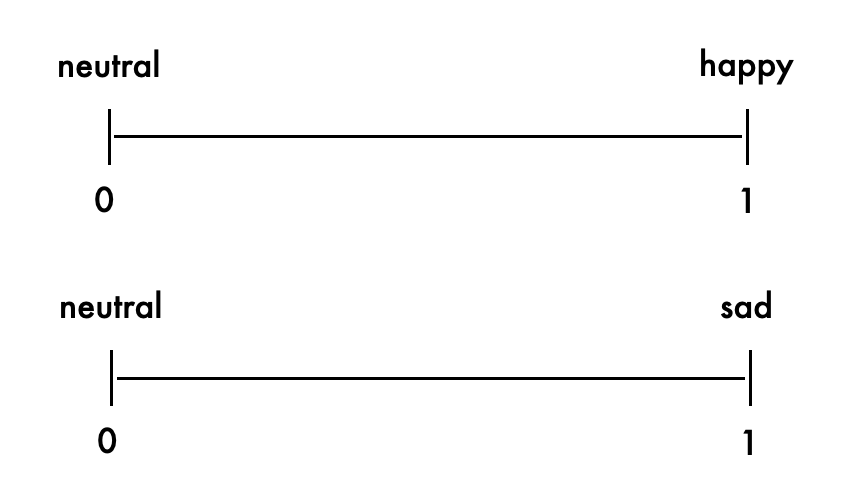
Dimensions identified are effectively binary, so for a feature such as happiness, we need 2 dimensions, both starting at zero or neutral, but then increasing for both happy and sad. One would expect that these dimensions are mutually exclusive - they both cannot be positive at the same time. Explainability can be effected in a pretty blunt force way here - which inputs cause each dimension to be activeated highes? Collect enough examples for each dimension, and you can have an LLM just descrive the common feature to each input.
SAE latent simension compression is in opposition to the type of dimensions encoded by for example a Variational Autoencoder (VAE)
Variational Autoencoder VAE
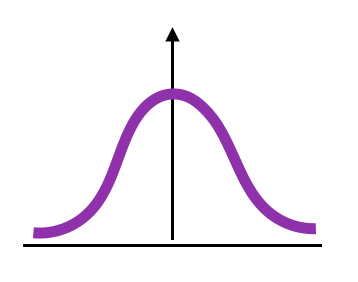 The feature space for a variational autoencoder is bottlenecked - smaller in dimensionality than the input feature space. This acts as a great way to allow compression, and also has been used widely in the generative image space.
The feature space for a variational autoencoder is bottlenecked - smaller in dimensionality than the input feature space. This acts as a great way to allow compression, and also has been used widely in the generative image space.
Each dimension is more expressive however, aiming to encode both ends of the same latent direction. Again thinking about happiness, both ends of the spectrum are captured in the same dimension but at either end. This is a particularly useful feature for use in generation models - one can interpolate along a dimension to control the output, but this is less useful in the intepretability space, as identifying these dimensions is more difficult, especially when features don’t tend to have a natural opposite.
Digging Deeper: Why This Release is a Big Deal
1. Comprehensiveness
While previous work often focused on single layers or small subsections of activations, Gemma Scope covers every layer and sublayer of Gemma models. This allows for deep, systemic interpretability experiments across the entire model stack. For researchers interested in the evolution of representations across layers, this dataset is invaluable.
2. Open Access
The Gemma Scope weights are available on Hugging Face (link), along with interactive tools like Neuronpedia (link). This openness enables reproducibility and collaborative research.
3. Scalability
Gemma Scope isn’t just about training a single SAE—it’s about scaling SAE techniques to large models. With Gemma 2 models ranging from 2B to 27B parameters, we can now see how sparse representations behave as models grow larger. Do the features split? Do they become more specialized? This release gives researchers the tools to answer these questions.
4. Real-World Utility
Gemma Scope opens the door for practical interpretability applications:
- Detecting hallucinations: By analyzing sparse activations, we might identify when a model is drifting into nonsensical territory.
- Debugging model behavior: Sparse activations allow researchers to trace and isolate the specific features driving a model’s decisions.
- Preventing deception: In safety-critical contexts, SAEs could help uncover subtle but dangerous model behaviors before they occur.
Why It Matters
Gemma Scope is more than just a set of pretrained autoencoders—it’s a milestone for the interpretability community. By making these tools open and comprehensive, DeepMind is accelerating the pace of research and democratizing access to techniques that were previously locked behind resource walls.
For researchers, the possibilities are endless: dive into the weights, analyze the latents, and help us all better understand the strange, beautiful, and superposed world of neural networks. Interpretability is hard, but with tools like Gemma Scope, it just got a little easier.
You can start experimenting today: Check out the models and explore the demo.
The demo at neuronpedia is awesome - the latent dimensions have been labelled by llm so you can see the utility of tools like these against your own inputs.