on
6 minutes to read
Modern BERT
A Much-Needed Update to an ML Workhorse
ModernBERT: Bringing BERT into the Modern Era
 When I joined the data science world, embeddings in NLP were all the rage. Word2Vec was widely used for transfer learning tasks. Newer architectures had allowed models at the time like ELMo (Embeddings from Language Models) which used bi-LSTMs to improve on the contextual representation - allowing for example the polysemic words like ‘bank’ or ‘play’ to be disambiguated depending on their surrounding context. At the time I joined, the transformer had just been released and a few folks: GPT, BERT were seeing some benefits in applying it to language modelling tasks.
When I joined the data science world, embeddings in NLP were all the rage. Word2Vec was widely used for transfer learning tasks. Newer architectures had allowed models at the time like ELMo (Embeddings from Language Models) which used bi-LSTMs to improve on the contextual representation - allowing for example the polysemic words like ‘bank’ or ‘play’ to be disambiguated depending on their surrounding context. At the time I joined, the transformer had just been released and a few folks: GPT, BERT were seeing some benefits in applying it to language modelling tasks.
The GPT, decoder only, model proved to be pretty useful (sources needed) at text generation tasks - We seem to have moved over to calling them LLMs or Large Language Models, now but I’m not really sure exactly when that happened - I guess this is strategic branding by foundation model companies away from the GPT terminology that OpenAI have so closed in on.
Since then BERT and the variants of the BERT architecture have been running the show in the transfer learning space. The LLM world has progressed in leaps and bounds, and now LLMs that require some grounding in fact at test time are still relying on BERT based models to ensure they have the right context readily available at aiding their generation. ColBERT is one of the most popular current models for the “R” in “RAG” or Retrieval Augmented Generation.
As I write this, the Bert Base Uncased model is the second most popular model downloaded from Huggingface, having over 64 million downloads in the last month. 6 in the top 20 are BERT variants.
But here’s the thing: most of these BERT variants are still running on architectures that haven’t changed much since BERT’s release in 2019. While LLMs have rapidly evolved with improvements like rotary embeddings, flash attention, and better activation functions, encoder models have largely stayed frozen in time.
Enter ModernBERT: a complete modernization of encoder-only models that brings them firmly into 2024. Theyve even (I assume) given a nod to Daft Punk in the paper title: “Smarter, Better, Faster, Longer”
What is ModernBERT?
ModernBERT is a new family of encoder models that modernizes the BERT architecture by incorporating the best improvements developed for LLMs over the past five years. But it’s not just about adding fancy new components. ModernBERT was designed from the ground up with three key principles in mind:
- Modern Architecture: Incorporating proven improvements like rotary positional embeddings (RoPE), GeGLU activations, and flash attention
- Efficiency First: Designed to run blazingly fast on common GPUs through careful hardware-aware optimization
- Longer Context: Native 8192 token context length (16x longer than original BERT) without compromising performance
The team released two models:
- ModernBERT-base: 149M parameters
- ModernBERT-large: 395M parameters
Both were trained on 2 trillion tokens of data, including a healthy dose of code and technical content that older encoder models typically lack.
Why This Release is Important
There are three key reasons why ModernBERT represents a major step forward:
1. Unmatched Efficiency
ModernBERT isn’t just better, it’s significantly faster. The models process tokens almost twice as fast as other recent encoders, while using notably less memory. This is achieved through careful architectural choices like:
- Alternating between global and local attention (every third layer uses global attention)
- Whole-model unpadding that removes the compute waste from padding tokens
- Hardware-aware model design targeting common inference GPUs
For example, ModernBERT-base can process batches twice as large as any other base-sized encoder on both short and long contexts, while maintaining higher throughput.
2. Strong Performance Across the Board
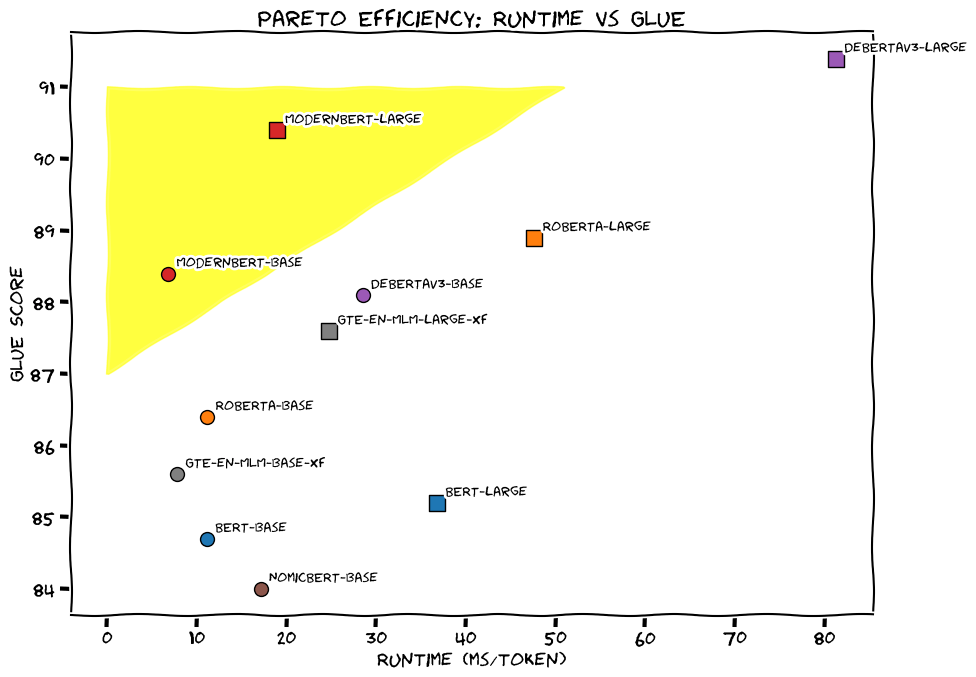
ModernBERT sets new state-of-the-art results for encoder models across a wide range of tasks:
- Best GLUE scores for MLM-trained models (beating specialized models like DeBERTaV3)
- Leading performance on both short and long-context retrieval
- Exceptional results on code-related tasks thanks to code-aware training
3. Practical Long Context
While other models have attempted long context through various tricks, ModernBERT handles long sequences efficiently through its alternating attention pattern and careful optimization. The models can process 8192-token sequences without the dramatic slowdowns seen in other long-context encoders.
The Technical Innovation: Making It All Work Together
What makes ModernBERT special isn’t any single improvement, but rather how it carefully combines multiple advances:
- Modern Transformer Upgrades:
- RoPE positional embeddings for better handling of sequence position
- GeGLU activation functions for improved model capacity
- Careful bias term removal to optimize parameter usage
- Pre-normalization for more stable training
- Efficiency Improvements:
- Alternating global/local attention with 128-token sliding windows
- Flash Attention integration for faster computation
- Whole-model unpadding to eliminate padding overhead
- torch.compile optimization for improved throughput
- Hardware-Aware Design:
- Model dimensions chosen to maximize GPU utilization
- Careful attention to tensor core requirements and tiling
- Optimization for common inference GPUs like the RTX 4090
What It Means for the Field
ModernBERT represents a big jump forward for encoder models, showing that there’s still substantial room for improvement in this architecture class. It demonstrates that by carefully combining modern improvements with efficiency-focused design, we can create models that are both more capable and more practical to deploy.
For practitioners, ModernBERT offers a compelling upgrade path: better performance across the board, significantly improved efficiency, and long-context capability, all while maintaining backward compatibility with existing BERT-style workflows.
The models are open source and available, along with the FlexBERT framework that enables easy experimentation with the architecture. You can start exploring at github.com/AnswerDotAI/ModernBERT.