on
6 minutes to read
Deepseek's Janus Models
Multimodal understanding and generation from the same models.
Janus
Its October 2024. Towards the end of a slow year for AI. Can you imagine?
Anyway, Deepseek a cracked team of AI Engineers in China who, facing a shortage of NVIDIA GPUs on account of a trade embargo imposed by the States, got really good over the last year at squeezing everything out of the cards that they do have.
I wanted to dig into their Janus paper, and then the follow up Janus Pro papers because the idea of multimodal understanding and generative models is attractive on account of the day job, and also because efficiency. Efficiency rocks.
Janus Architecture
The key focus from Janus is the architecture of the model. The first posted image from GPT4o goes as far as suggesting the architecture:
A GPT-4o generated image — so much to explore with GPT-4o's image generation capabilities alone. Team is working hard to bring those to the world. pic.twitter.com/5mO5aQxbaK
— Greg Brockman (@gdb) May 15, 2024
In principle, the core of the model receives tokens in, and outputs tokens. The tokens out can either be decoded by the image generation head, or decoded by the text decoding head. What Janus does slightly differently is to use separate image encoders depending on the task at hand. The intuition behind this is that when understanding images, the encoder needs to be able to capture the high level semantics of the image, whereas for generation the encoder is required to get the fine grained detail, and the spatial structure.
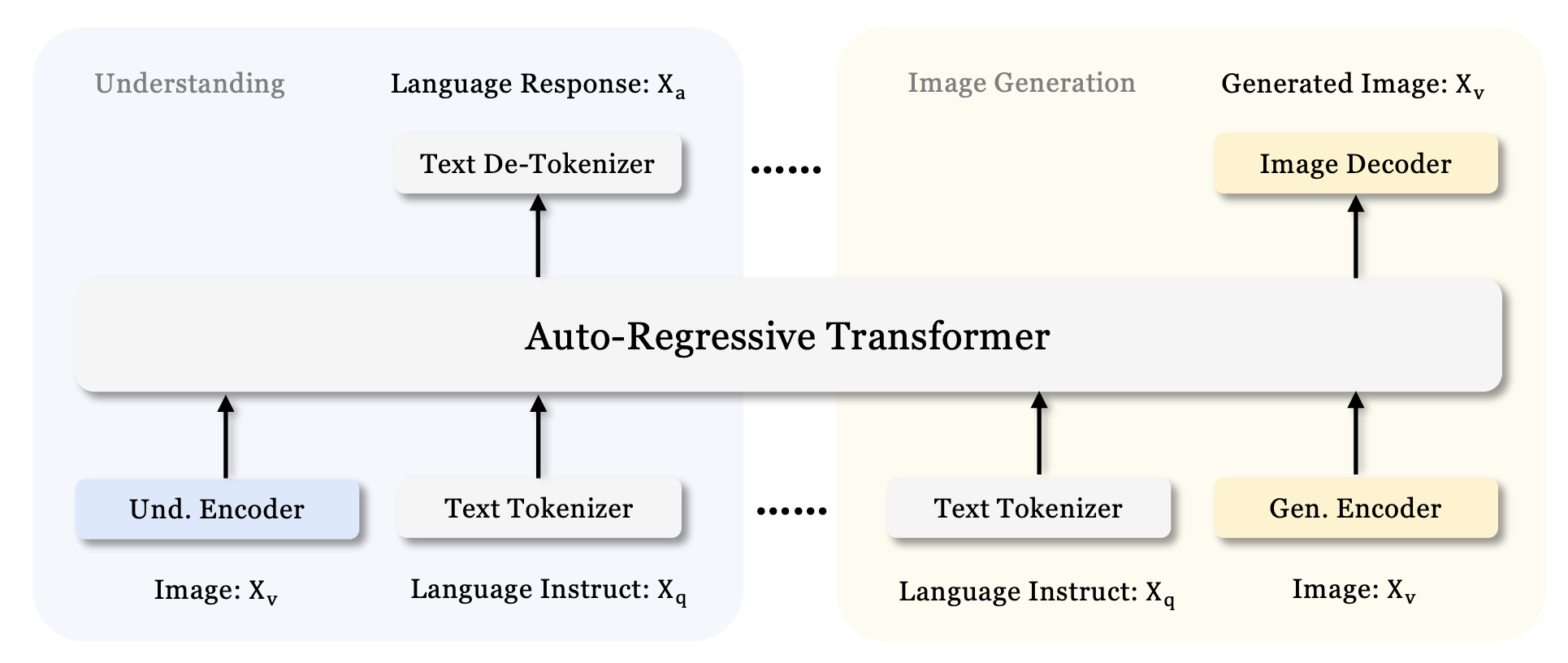
Encoders
Given they needed 2 encoders, they went shopping, and found 2 well suited to the task.
For Encoding images in the task of understanding they went with the SigLIP image encoder specifically SigLIP-Large-Patch16-384 - 16x16 pixel patch size, 384x384 pixel image size. Sensible - SigLIP feels a natural successor to CLIP, adept at encoding images and text into the same latent space.
For encoding in the task of generation, they opt for a vector quantized autoencoder from this paper an autoregressive image generation model from bytedance. This has a ~16k codebook size.
Both encoders need an adapter layer each between them and the 1.3B deepseek-LLM. These are 2 layer MLPs to map the tokens into the same space as the text.
Training
Training is really where Deepseek come into their own, so this is the fun bit.
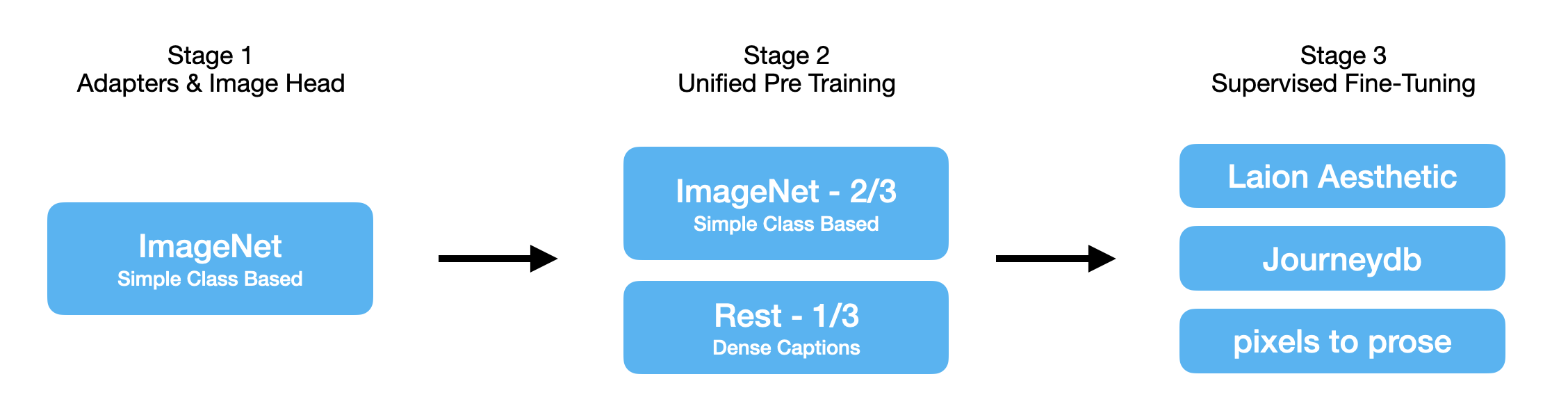
Training happened over three phases
Stage 1: Train the Adapters and the Image head
Everything in the image encoders and LLM is frozen, they train the adapter layers between image encoders and LLM, and then the image generation head.
Stage 2: Unified Pretraining
This is where the bulk of the training happens. Interestingly for the generation part, they train to generate using imagenet for the first 2/3 of the run, and as the model has learnt the basic pixel densities, they switch to using more dense captioned image text pairs from a wide array of sources.
Stage 3: Supervised Fine Tuning
At this stage, the generation head is frozen, and the model is fine tuned to improve its ability to follow instructions and improve in dialogue scenarios.
Looking at the datasets used at each stage for generative training:
Janus → Janus Pro
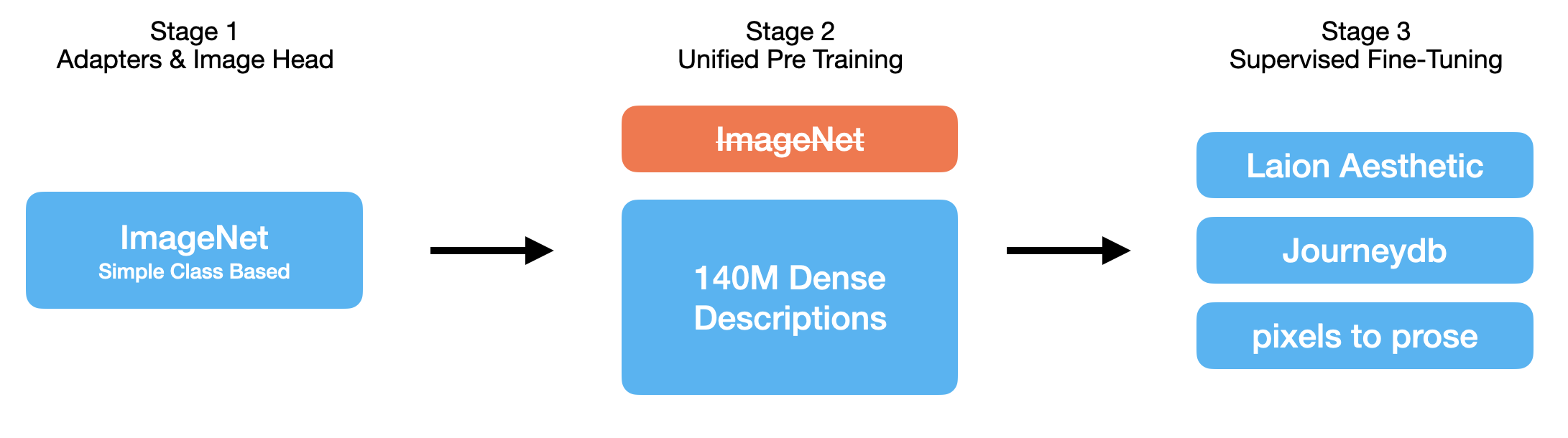
Comparing the two papers, where they scale up the base LLM from 1.3B parameters to use the 7B model in Janus Pro, they also update the training recipes and are gracious enough to highlight the differences:
Stage 1
They increase the number of training steps from 10k to 20k, still using just the Imagenet dataset for generative image training.
Stage 2
Imagenet data is dropped from this stage, and a new dataset of 72M synthetic, high aesthetic scoring images are used - totalling 50% of the generative image training set. Additionally 90M image text pairs from Deepseek VL2 for the understanding tasks.
Stage 3
Adjusting the data ratio mix for the tasks - slightly reducing the proportion of text-to-image data, they observe that they can maintain strong visual generation capabilities while achieving improved multimodal understanding performance.
Janus Pro Generative Image Training Dataset
Effect
As you’d expect, the changes made between Janus and Janus Pro come with an increase in a bunch of hand-picked metrics. I’m sure these will be laid bare by the community when and if the model sees significant use.
Cost
As with other models out of Deepseek (R1 Ahem) the training cost is an important thing to estimate, chiefly because they seemingly face the same GPU constraints that many of us GPU-poor™️ face. Back of an envelope calculation suggests that the 7B pro model comes in at a shade over $350k, with 95% of that spend coming from the unified pre-training time by sample count.
Conclusion
What stands out about Janus and Janus Pro is not just their technical achievements, but how they represent a thoughtful approach to multimodal AI under constraint. The team’s decision to use specialized encoders for different tasks, combined with their efficient training strategy, shows that innovation doesn’t always require unlimited resources. As we move forward in the AI landscape, perhaps this kind of resourceful engineering by making the most of what’s available rather than throwing more compute at problems will become increasingly valuable.
The progression from Janus to Janus Pro also demonstrates a clear understanding of what matters in multimodal models: balanced capabilities across both understanding and generation, achieved through careful dataset curation and training regime optimization.
It’s a reminder that sometimes the most interesting advances come not from scaling up, but from thinking differently about the problem at hand, and I love thinking differently